理解内存重排序以及为什写无锁多线程代码时很重要
George Cao于2020年02月29日 内存模型 多线程 原子性 多线程 内存重排序
此系列前一篇文章中,用原子操作实现无锁多线程,我介绍了无锁多线程:并发软件中线程同步的底层机制。
基于原子操作,也就是CPU直接执行的不能细分为更小步骤的机器指令,相比传统的同步原语如互斥锁和信号量,无锁多线程提供了更快和更细粒度控制的同步机制。
一如既往的,能力越大,责任越大。无锁编码中你更接近本质,因此理解机器是如何工作的以及机器的特性是非常有益的。
本文中我会介绍一些硬件(和软件)对无锁代码产生的非常重要的副作用。这也是惊叹计算机内部小型世界的复杂性的机会。
本系列中的其他文章
-
多线程简介 - 一步一步走进并发的世界
-
线程同步简介 - 多线程应用中最常见的并发控制方法之一
-
用原子操作实现无锁多线程 - 底层线程同步
内存重排序或者不愉快的惊喜
现有编程课程首先要教你的是计算机如何顺序执行用源代码写出的指令。一段程序就是文本文件中的一系列操作,处理器会从上到下执行这些操作。
意外的,这常常是一个谎言:你的机器有能力按需调整一些底层指令的执行顺序,尤其是内存读取的时候。这个诡异的修改,叫做内存重排序,会发生在硬件和软件层面,且经常是因为性能的原因。
内存重排序开发出来旨在利用那些原本要浪费掉的指令周期。这个技巧能大幅度提升你程序的执行速度;另一方面,它可能对无锁多线程造成严重破坏。我们马上能看到为啥。
我们先来仔细看一下内存重排序这种不可预知的行为存在的原因。
内存重排序总结
程序想要执行,必须加载进主内存。CPU的任务就是执行存储在那的指令,同时在必要的时候读数据或者写数据。
随着时间的推移,这种类型的内存和处理器比起来变得非常慢。例如,一个现代的CPU一个纳秒内能够执行10个指令,但是需要纳秒的许多倍时间从主内存中读取数据!工程师们不喜欢时间就这样浪费了,所以他们给CPU配上了容量很小但是速度非常快的特殊内存,我们称之为缓存。
缓存是为了避免和慢速主内存交互,用来存储CPU最常用的数据的。如果CPU需要从主内存读取或者写入主内存,它首先检测缓存看是不是有所需数据的副本。如果有,处理器就直接从缓存读取或者写入缓存而不会等待相比较慢的主内存的响应。
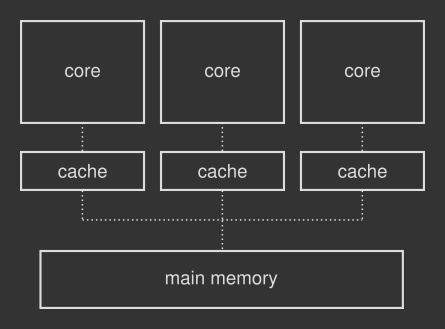
现代CPU有多个核心组成的,核心(core) 是真正执行计算的组件。每个核心拥有自己的独立缓存,如下图所示:
Figure 1. 多个核心通过缓存和主内存交互的简化模型。这也叫做共享内存系统,因为主内存被多个实体访问。
总而言之,缓存能让计算机运行更快。更准确的说,缓存通过让处理器总是繁忙和高效来帮助处理器不要因为等待主内存响应而浪费宝贵的时间。
内存重排序作为优化技巧
很明显缓存机制增加了多核场景下系统的复杂性。现在你需要详细的规则来决定数据如何在不同的缓存间流动,来保证每个核心有最新版本的数据,称之为缓存一致性协议,他可能引发非常大的性能下降。所以工程师们就设想用内存重排序来充分发挥每个核心的作用。
内存重排序为什么会发生的理由有很多个。比如,考虑2个核心同时访问同样的内存块。核心A从内存读取数据,核心B写入数据到内存。内存一致性协议可能会强制核心A等待核心B将本地修改的数据写回到主内存,这样核心A就能读到最新的数据。这个等待的核心可以选择提前执行其他内存指令,而不是浪费珍贵的指令周期啥也不做,即使这个和你在程序中明确的代码顺序不一样。
当特定的优化开启了,编译器和虚拟机也会启用重排序指令。这些变化发生在编译时,可以通过汇编码或者字节码很容易的看到。软件内存重排序是充分利用底层硬件可能提供的特性来让你的代码运行的更快。
硬件内存重排序的具体样例
考虑下面用硬件伪代码写的样例。程序的每一个步骤都对应一个处理器指令:
x = 0
v = false
thread_one():
while load(v) == false:
continue
print(load(x))
thread_two():
store(x, 1)
store(v, true)上面的代码片段中2个线程并发运行在2个不同的核心上。第1个线程等待第2个线程将v设置为true。让我们假设store()和load()都是读取内存的原子CPU指令。
你预计第1个线程在屏幕上打印出什么?如果他在线程2之前启动(并不总是这样的),就没有正确的答案了。如果没有重排序发生,你可能会看到1。尽管如此,如果第2个线程中的存储指令发生重排序,v 的更新也可能发生在x之前,打印语句可能打印出0。相似的,内存重排序也可能发生在第1个线程中,也就是x的加载可能发生在v的检测之前。
内存重排序对多线程的影响
硬件内存重排序在单核计算机上没有问题,因为线程是操作系统控制的软件结构。CPU就是收到连续的内存指令流。指令还是可以被重新排序,不过要符合一个基本规则:给定内核的内存访问看上去就像和代码写的一样。所以,内存重排序可能会发生,但是只在不影响最终结果的前提下。
这个规则也适用于多核场景下的每个单核,但不适用于不同操作同时跑在独立的硬件上的情况(真并行(true parallelism))。让你的线程跑在两个物理内核上,你就会碰到上面样例中的各种诡异问题,更不用说让编译器和虚拟机执行重排序了。
常规的如互斥锁和信号量等锁同步机制是设计用来处理硬件和软件层面的内存重排序的。毕竟他们是上层技术。
不过,应用无锁方案的多线程程序更接近底层:就像上一篇文章看到的,它利用存储和加载原子指令来同步线程。 搞笑的是这些操作可能被重排序,从而破坏了你的严谨计划。
如何解决内存重排序的问题
你肯定不会基于一些随机变化的东西构建你的同步机制。这个问题可以通过引入内存屏障的方式来解决。内存屏障是强制处理器按照可预知的方式访问内存的CPU指令。内存屏障的工作方式类似路障:内存屏障之前的指令保证先于内存屏障之后的指令执行。
内存屏障是硬件层面的:你得直接和CPU交互。这是一个底层的解决方案,且不利于程序的可移植性。解决这个问题最好的方式是软件层次,利用操作系统,编译器或虚拟机提供的工具。
尽管如此,软件工具也仅仅是中间阶段。为了构建一个此问题的清晰的全景图,我们首先全局看一下所有可能在硬件或者软件系统中的内存场景。内存模型 在这个过程中发挥重要作用。
内存模型
内存模型是抽象的方式描述系统中涉及到访问和重排序内存可能或者不可能发生的事情。处理器和编程语言会实现一个,尤其是利用多线程技术的时候:内存模型同时适用于硬件和软件层面。
当系统对改变内存操作顺序非常谨慎,我们说系统遵循强内存模型。相反的,弱内存模型 中你可能碰到各种各样的重排序。比如,x86系列的处理器属于前一类,而ARM和PowerPC处理器则属于后一类。软件层面又是怎么样的呢?
软件内存模型的好处
硬件内存模型存在的原因很明显,而对应的软件内存模型让你能够按需重排内存访问顺序。这个特性在你写无锁多线程代码的代码能帮很大的忙。
例如,为了避免同步机制中不受欢迎的原子操作的重排序,编译器可以编译出遵循强内存模型的机器码。当底层硬件实现的是弱内存模型的时候,编译器会通过加入正确的内存屏障指令来最大限度的提供你需要的内存模型。编译器也负责软件层面的内存重排序指令。使用软件内存模型可以解耦硬件细节。
细粒度内存模型
强和弱内存模型是对内存操作如何重排序的理论上的分类。具体到真实的编码,大多数支持原子操作的编程语言会提供3种控制内存重排序的方式。我们仔细看一下。
1)顺序一致
较少干扰的内存重排序方式就是根本不重排序。这是强内存模型的一种形式,称之为顺序一致:这正是解决上面提到的所有无锁多线程问题所需要的。禁用重排序能让你的多线程程序容易理解:源代码是按照书写顺序执行的。
顺序一致给并行代码执行加了另外一个重要特性:它强制了所有线程中的所有内存原子操作的整体顺序。为了更好理解这句话,考虑如下的硬件伪代码样例:
x = 0
y = 0
thread_A:
store(x, 1)
thread_B:
store(y, 1)
thread_C:
assert(load(x) == 1 && load(y) == 0)
thread_D:
assert(load(x) == 0 && load(y) == 1)我们暂时不考虑单个线程内的内存重排序,看一下全局情况。如果线程按照A-C-B-D的顺序运行,线程C能看到x == 1和y == 0,这是因为线程C是在线程A和线程B之间运行的,因此线程C的断言不会失败。但是这也是问题所在:顺序一致强加的全局顺序迫使线程D看到与线程C一样的事件,因此线程D的断言会失败。线程D不可能看到和线程C不一样的存储顺序。换句话说,线性一致下,所有的线程都看到同样的东西。
就像前面说过的,这是一个非常直观和自然的思考多线程执行的方式。尽管如此,顺序一致也取消了内存重排序带来的任何硬件或者软件优化:这通常会引起严重性能瓶颈。顺序一致有些时候是必要的,比如多生产者-多消费者情况下消费者必须按照生产者的生产顺序消费。
2)获取-释放顺序
获取-释放 是强和弱内存模型的中间状态。首先,获取-释放和顺序一致工作方式相似,除了没有全局执行顺序。我们在看一下上面的那个例子:在获取-释放情况下,线程D是允许看到不同于线程C的事件,因此线程D的断言有可能会通过。
全局顺序的缺失其实是个副作用。获取-释放是针对特定共享原子变量在多个线程之间同步的。也就是说,你在线程A和线程C之间同步共享变量x,使得线程C只能在线程A完成写入之后才读取。这种情况下,y 并没有考虑进去,所以你可碰到任何针对它的重排序。
具体来说,支持这种有序性的编程语言允许你将内存访问标记为获取或者释放。当线程B触发某共享变量上标记为获取的原子加载操作,线程A中的同一个共享变量上标记为释放的原子存储可确保线程B将看到线程A执行的完整且不是重新排序的内存事件序列。我知道这比较烧脑,不过这是互斥锁的基础:关键区和它保护的区域就是用这个构建的(获取-释放名字来源于互斥锁术语,也就是获取和释放互斥锁)。
获取-释放允许更多的优化机会,因为仅有部分内存重排序不被允许。换句话说,你的程序更不容易推理分析了。
3)松散顺序
还有一种弱内存模型的形式。松散顺序 的情况下,你写程序的时候根本不关心内存重排序。编译器和处理器可以尽可能的优化程序执行。当然了内存操作的原子特性是保留下来了:这在增加共享计数器的时候非常有用,这种情况下操作必须是原子的才能让其他线程不能看到未完成的中间状态。
松散有序性不保证任何特定的内存重排序,所以这不是可以安全使用的线程同步工具。另一方面,这也允许使用任何内存技巧来提升你的多线程程序的性能。
下一步?
这篇文章中,我想对内存重排序问题以及其存在的原因和它对无锁多线程的影响有一个全面的了解。接下来我会写一些使用原子操作的C++代码来实践一下。
为什么是C++ ?因为C++语言近期引入了非常详细的内存模型,使得你能够细粒度的控制C++原子对象的内存重排序操作。我相信这是一个很好的方式去看顺序一致,获取-释放和松散有序在真实的场景下是如何一起工作的。祝我好运吧:)。
参考
-
AA. VV. - C++ Reactive Programming
-
Paul E. McKenney - Memory Barriers: a Hardware View for Software Hackers
-
cppreference.com - std::memory_order
-
GCC Wiki - Memory model synchronization modes
-
doc.rust-lang.org - Atomics
-
Herb Sutter - Atomic Weapons 1 of 2
-
The ryg blog - Cache coherency primer
-
The ryg blog - Atomic operations and contention
-
Bartosz Milewski - C++ atomics and memory ordering
-
Bartosz Milewski - Who ordered sequential consistency?
-
StackOverflow - Memory barriers force cache coherency?
-
StackOverflow - How does the cache coherency protocol enforce atomicity?
-
StackOverflow - Does a memory barrier ensure that the cache coherence has been completed?
-
StackOverflow - C11 introduced a standardized memory model. What does it mean? And how is it going to affect C programming?
-
StackOverflow - How do memory_order_seq_cst and memory_order_acq_rel differ?
-
StackOverflow - What do each memory_order mean?
-
Just Software Solutions - Memory Models and Synchronization
-
Wikipedia - CPU cache
-
Wikipedia - Cache coherence
-
Wikipedia - Memory barrier
-
Wikipedia - Memory ordering
-
James Bornholt - Memory Consistency Models: A Tutorial
-
Preshing on Programming - Memory Ordering at Compile Time
-
Preshing on Programming - Memory Barriers Are Like Source Control Operations
-
Linux Journal - Memory Ordering in Modern Microprocessors, Part I
-
Doug Lea - Using JDK 9 Memory Order Modes
本文译自https://www.internalpointers.com/post/understanding-memory-ordering,英文读者可直接阅读原文。