<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="org.reploop.mapper.EntityMapper"> (1)
<select id="selectAll" resultMap="BaseResultMap"> (2)
select *
from tb_entity
</select>
</mapper>MyBatis Mapper中的SQL生成
乔治于2022年06月24日 Ognl SQL MyBatis 优先级 表达式求值 实体关系图 实体关系图
MyBatis作为和Hibernate相比来说是一个轻量并且非常灵活的ORM框架,见过的Java项目中大部分都是使用MyBatis。MyBatis在运行时是支持日志输出SQL语句的,进而可以通过SQL做一些分析。如果要在编译时期做一些就像Java语言的静态分析之类的事情,通过解析XML的文件也是一个办法。本文通过项目mybatis-sql-dump来介绍一下如何从XML中生成SQL语句。
现在数据库设计越来越的不遵守范式,数据库之间的主键和外键约束关系都不会落到数据库中,而是在应用程序中。因此在数据库中大部分情况下下看到的就是一些简单而独立的表,表之间的关系都弱化了,只有客户端SQL语句执行的时候才知道涉及的表之间的约束关系。通过联合查询的SQL来推断表之间的约束关系是本文的第2个目的。
MyBatis工作机制
MyBatis通过解析XML,通过namespace将XML文件和Java接口联系起来。然后将XML中的SQL语句解析为MappedStatement,并通过其id属性值和Java接口中的方法名对应起来,随后用生成代理的方式为接口中的每个方法行程代理,方法被调用的时候再通过方法名反向映射到XML中的SQL语句并执行。
package org.reploop.mapper;
class Entity {
// Properties
}
public interface EntityMapper {
List<Entity> selectAll(); (2)
}| 1 | namespace就是Java中的Mapper接口 |
| 2 | XML中id对应Java接口中的方法 |
生成SQL
SQL语句是在解析生成MappedStatement的过程中解析并生成SqlSource,然后通过其方法:
BoundSql getBoundSql(Object parameterObject);能得到一个BoundSql实例,最后BoundSql.getSql()就得到了SQL语句。
如果我们在XML里面写的就是单纯的SQL语句,那么到这里就结束了。实际上MyBatis还通过Ognl支持通过表达式求值的方式来根据入参来动态的调整SQL语句的输出。
SqlSource
SqlSource实质上是一个树形结构,体现了XML的嵌套结果的解析结果,然后执行getBoundSql的时候可以看作是层序遍历这个树,并且通过入参作为输入,对Ognl表达式进行求值(或者绑定变量)后的结果就是SQL语句了。
这个下面这个select语句中:
<select>
select * from ${tableName} where deleted = 0 (1)
<if test="userId != null"> (2)
and user_id = #{userId,jdbcType=INTEGER}
</if>
</select>| 1 | ${tableName}这个变量在SQL语句生成阶段就会替换为入参中ableName这个变量的值; |
| 2 | 这个test内容是一个ognl表达式,只有入参中userId不为null的情况下,也就是表达式求值为真的情况下where子句中的第2个条件才会生效 |
因此我们要生成完整的SQL语句,就需要解析这个表达式,收集表达式中需要的变量,以及为了能够让表达式求值结果为真,给变量合适的值。这样我们就需要解析Ognl表达式,并且走一遍表达式求值,从而推断出合适的变量值。
Ognl表达式
MyBatis集成了Ognl表达式的解析,解析完之后同样也是一个表达式语法树(AST),而且是带有操作符的语法树。Ognl表达式中的操作大部分情况下最多是2个操作数,所以这个语法树也可以是一颗二叉树。

表达式求值
拿到表达式树之后,我们可用深度优先遍历(Depth-First Search)的方式遍历这棵树,并在遍历的过程中收集变量,并根据其操作觉得该变量的值,使得表达式求值结果为真。
其实深度优先遍历的输出就是操作树的后缀表达式,而后缀表达式的求值则使用双栈(Stack),一个操作符栈,一个操作数栈遍历一遍就可以完成求值。一般的大学数据结构课程肯定是学过的。
实体关系图(ER-Diagram)
得到合法SQL之后就可以利用SQL解析器JSqlParser分析,并通过JOIN语法来推断数据库表之间的主键和外键约束关系,之后通过graphviz来生成可视化的图片。
结论
本文本是想通过现成的MyBatis框架本身就解析XML文件,而不是从0开始写一个解析符合MyBatis的规范的XML解析器,这个过程有一个不太完美的地方,就是如果XML中依赖了项目中的类,比如MyBatis的ParameterType,ResultMap或则typeHandler是个业务自定义的实现类,那么这个过程是需要把这些类都加入到classpath中去的,这样才能正确运行。
我们可以通过定制classloader的方式来解决,不过前提是XML的Mapper所在的项目需要提前编译好,这样才能通过定制classloader的方式指定搜索路径,来支持类的加载。
参考
-
JSqlParser, JSqlParser
-
MyBatis Spring Adapter, https://github.com/mybatis/spring
-
Expression Evaluation, https://cs.lmu.edu/~ray/notes/expressionevaluation/
服务开发的几个原则
乔治于2022年05月17日 微服务 持续集成 持续部署 构建 研发环境 分布式配置中心
开发服务类系统大体上分为以下几个步骤:编码|配置|打包|构建|部署。这个过程中涉及环境,代码,配置,构建、打包产出物,到最后的运行环境。

这里面的环境是一个静态配置,一般来说就是本地(local),开发(dev),测试(test),预发(staging)和生产环境(prod),更多的是用来标识与选择环境。可参考研发环境的设计思路了解更多。
每个步骤的结构都独立持久化到对应的存储中,作为后面步骤中的输入,像极了管道(Pipeline)的工作方式。
几个原则
-
代码和配置分离
-
代码只关注业务逻辑,不用操心部署环境以及静态配置
-
-
环境需要的配置交给分布式配置中心来管理
-
配置集中管理
-
-
代码编译打包为目标环境的机器码
-
所需要的配置最小化,比如环境的选择,Profile的指定等
-
-
构建服务将根据目标环境构建可部署的包
-
将上一步中基本打包结果构建为容器化的镜像
-
-
部署服务交给专门的CD部署系统来统一规划
-
发布与回滚都基于镜像来操作
-
-
运行时通过分布式配置服务加载环境配置
-
配置中心来回避配置散落到代码中,因为配置比代码变化更频繁
-
结论
研发划分的粒度越细,需要的职责也多,相应的人也会多一些。
多人协作研发环境的设计思路
乔治于2022年04月24日 研发环境 协作 云原生 虚拟化 容器化 资源隔离
一般公司的研发环境至少会分为:开发(dev),测试(test)和线上(prod)。这个大概是开发下意识就会有的基本思路。之所以分环境,主要是为了团队协作顺畅和线上系统稳定。
环境划分
从系统稳定性的角度,开发人员可以随时变更开发环境,稳定性最差;测试环境供测试团队使用,或者研发之外的产品,运营团队来测试,验收,要有一定的稳定性;线上或者生产环境是面向真实用户的,稳定性要求最高。对线上环境的变更需要有一定的流程和规范。有些在上线之前还可以有一个预发布环境(staging),此环境是一个准生产环境,使用的资源都是线上的资源,只是服务入口对用户是隐藏的,一般是上线前内部评审使用的环境。这个功能也可以用测试环境代替,但是一般测试环境数据没有线上规范,可能会有部分效果看不到。
从用户的角度,环境可归类为线上和线下两部分。线上环境包含生产和预发布环境,线下环境包含开发和测试环境。开发者一般都需要本机开发调试,所以开发环境又可以多一个本地(local)环境。
最后可以组成一个本地,开发,测试,预发布和生产5个环境。不同的团队规模可以酌情全部使用,或者简化省略一部分环境。最简单的就是维护一个生产环境,开发直接变更生产环境,只是从团队协作和业务稳定的角度看风险非常高。
从团队协作的角度,系统迭代通常会涉及开发,测试,运维,产品/运营到最终的用户/客户。不同开发之间的工作最好不要互相影响,不同测试之间的工作也不要影响。同时开发最好也不要影响测试工作,反之亦然。因此我们可以在一个环境内细分为多个分组(sharding/group),分组之间可以共用一部分环境,但是在不同分组各自变更的部分是相互独立而不干扰。比如线上环境如果要支持A/B测试的话,那么也可以分为2个组,一个测试组和一个对照组。不同的开发按照不同的功能(feature)为分组各自独立开发、测试和上线。比如一个支付团队在迭代支付服务,电商团队在做购物车的迭代,购物车流程是要用到支付服务的。这时候电商团队和支付团队就可以在开发环境中分别为两个功能分组,各自开发,而不会因为支付团队也在开发状态而影响电商团队的迭代开发。
最终的环境设计为下图的样子:

Figure 1. 环境规划
最后我们可以让不同的环境之间尽可能的保持相似或者一致,然后通过性能指标来调整资源分布,从而保持相似或者一致的前提下避免资源浪费。这样之后研发人员对各个环境会越来越熟悉,对于故障处理等紧急情况下的效率有很大的帮助。
落地思路
以上环境的规划,主要是通过各种资源的隔离来实现的。
隔离
区分环境主要是为了隔离,包括代码,数据库,消息队列,应用,负载均衡,基础设施比如机器以及网络环境等。还需要考虑依赖的第三方应用对环境的兼容性,比如第三方支付通道如微信支付不存在测试,应用要测试就是用微信支付线上的环境,线上的商户,线上的签名配置等。
物理隔离
这种隔离使用的是不同的物理机器,不同的部署服务,不同的代码仓库,不同数据库等等。这是物理级别的隔离,颗粒度比较粗的方式。比较常见的,比如把部分机器分配给测试组,其他人不能等。
软件隔离
不过随着虚拟化和容器化,以及云原生的趋势,很多物理资源都可以按需共享,这要就在软件层面实现隔离。常听说的命名空间(namespace)和多路复用(multiplex)理解起来就是软件层面实现的隔离资源。
资源
研发中涉及的资源最主要的就是代码和数据。
资源类型
- 代码
-
现在的SCM主要是git,可以很快速创建轻量级分支(branch)。
- 配置
-
分布式配置中心,可以每个环境共享一套配置项,应该是没必要做到每个分组一套配置项。
- 数据库
-
数据库连接字符串,主要是域名、端口设数据库名称。
- 服务器
-
一般是IP和端口,其中的IP也可以绑定到内部域名。或者使用内部DNS服务来解析域名和IP的配置。
- 依赖服务
-
主流是HTTP(S) URL,主要构成是域名、端口和context-path,亦或者是service-name等。
- 负载均衡
-
主流是HTTP(S),通过域名来使用Virtual Host来区分不同的环境。
资源命名
把资源先按照环境划分,每个环境在按照分组划分,然后形成对应的名字。 这个写出来就是:分组-环境-资源(sharding-env-resource)。这只是一个例子,实际上我们可以使用更多的维度来命名,就像TCP协议栈中的数据封装的方式一样,通过不停的打Tag或者加Header的方式继续扩展下去。
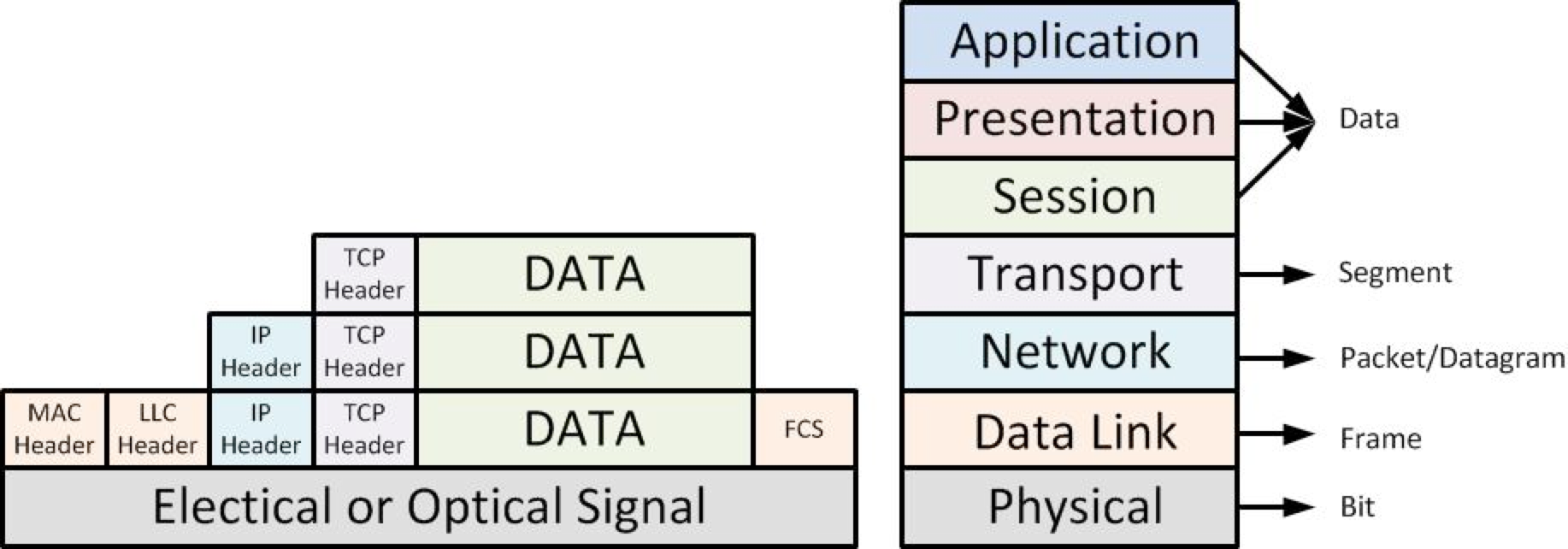
Figure 2. TCP/IP数据封装
如果我们把这些Tag按照一定的顺序连接起来,用容器的术语,我们也是在用命名空间(namespace)的概念来隔离资源了。从资源的角度看过去,我们就是在干sharding的事情,就像数据库的分库和分表一样的思路。
Tag的方式
常见资源的Tag方式:
-
代码: git branch是一个天然的tag
-
域名:子域名也是直观的的tag,比如tag.domain.com,f1-dev.domain.com, f2-test.domain.com
-
HTTP Request:
-
Query String: 参数的方式;
-
Header: x-shard=f1 or group=tag, env=test or dev;
-
Cookie: 跨请求无状态服务之间共享数据的方式;
-
-
Tag metadata: 直接在数据中附带tag元数据。 比如我们常说的对象存储服务,之所以叫对象存储而不是块存储,就是因为对象存储除了数据以外还有一部分元数据。
命名空间和另一个概念多路复用(multiplex)也有一定的相似性,都是通过命名来区分资源的。如果你是Web开发者的话,理解起来就特别顺,比如一台机器上的不同端口,一个端口上的不同协议,相同协议的不同域名,相同域名中的不同的context-path等等都可以将资源隔离开来而又共享了部分资源。
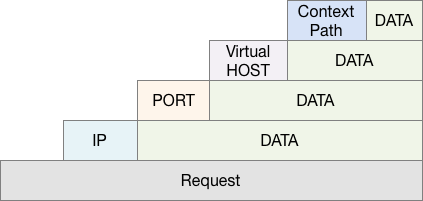
Figure 3. 应用的多路复用
资源创建与销毁
要做到上面的环境,最好是有一个程序化的创建与销毁各种资源的方式,最好的匹配就是k8s环境。比如说你要使用一个开发域名,需要起一个邮件发申请,等着审核系统逐级审核到最后运维团队在执行的话,就非常的不适用这么灵活的环境。
环境与分组(sharding)
这样我们就可以是用最直观的分组-环境-资源三个维度来尝试实现一个共享与隔离同时具备的灵活的研发环境。
-
每个功能(feature)都可以作为一个分组,通过代码仓库的分支号来区分;
-
每个功能都可以独立部署到对应的环境中,通过命名机制来在本环境内寻找相应的依赖资源;
-
对应环境中开发此功能涉及到的依赖服务能需要能够共享。
如何共享非变动的资源呢?通过Fallback机制或者动态路由来实现。
服务动态路由
每个环境都需要有一个默认的分组,如果没有指定分组的话,可以使用默认分组。这样我们就可以在Request的经过的服务中根据分组和环境来路由到不通的服务实例,做到环境的隔离和不同角色的稳定协作。
虽说如此,但是环境与环境之间应该要严格隔离的。就是开发环境严格的不能使用测试的数据库,更不能链接线上的数据库。测试数据的规范和覆盖率,数据不完备或者不规范,导致很多逻辑验证不规范,覆盖率不到。会导致很多的时候测试环境没问题,一到线上就有问题的现象。这个可以通过线上数据脱敏之后定期同步到测试环境,而避免在测试环境中直接连接线上数据库。
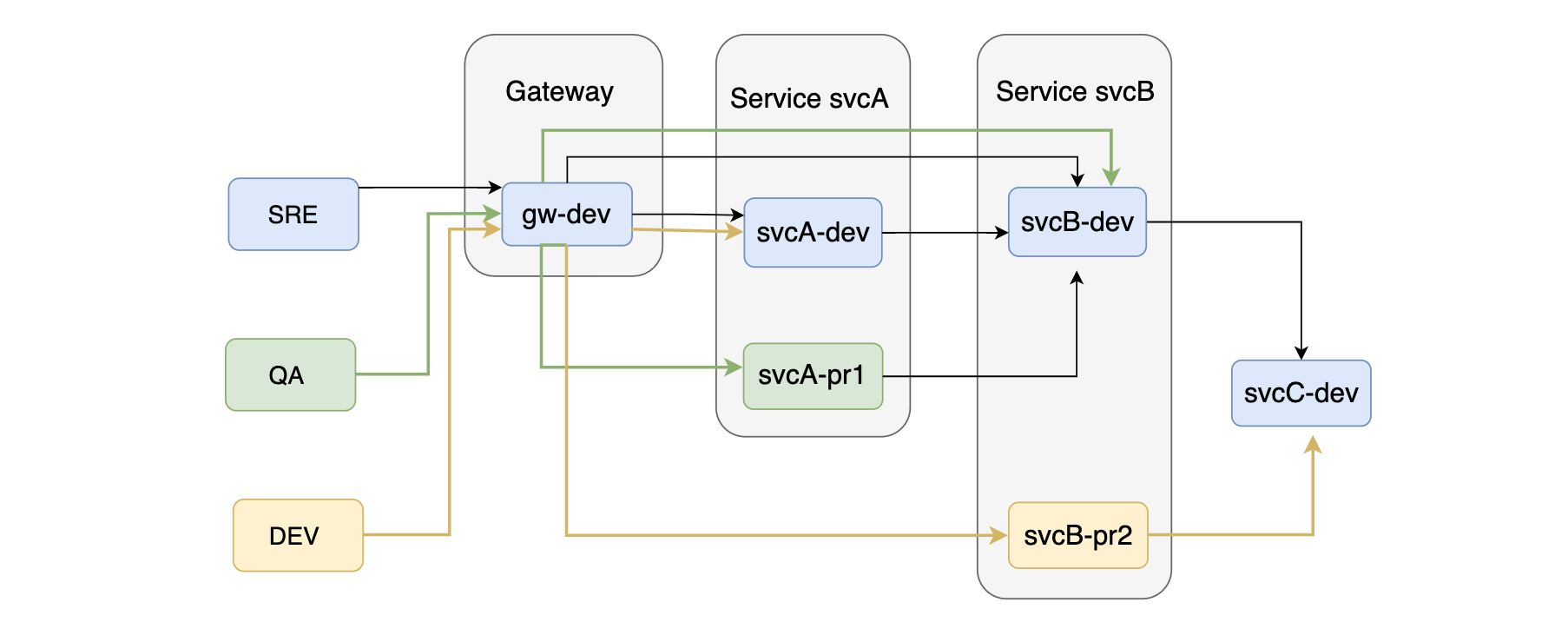
Figure 4. 服务动态路由
总结
基于以上对环境的理解,整个研发环境的设计需要涉及基础设施如网络,域名等,数据库连接字符串,各种中间件,Servlet容器,反向代理等各个环节的适配,从而来构建这个多人协作并行开发的高效环境了。这个过程可以参考SkyWalking等APM服务对开发人员透明的不侵入应用的集成方案。
参考
-
Sharma Rajesh, Dynamic Service Routing using Istio
-
Packet Networking, Data Encapsulation