用原子操作实现无锁多线程:底层线程同步
George Cao于2020年02月27日 原子指令 多线程 无锁 无等待 并发 算法
本文英文版经Federica Rinaldi仔细审阅过,谢谢。
"atom"在希腊语中拾不可再分割的意思。在计算机中一个任务被称为原子的是指他不能再细分了:它不能再拆分为更小的执行步骤了。
原子性 是多线程操作的一个重要特征:因为原子操作是不可在细分的,所以一个线程是不可能干扰另一个正在并发执行原子操作的线程的。例如,当一个线程原子写入共享数据,其他线程是没有办法读取到未完成的数据。相反的,当一个线程原子读取共享数据,这个数据就像是单个时间点上的数据。换句话说,就是没有数据竞争的风险。
在上一篇文章中,我介绍了所谓的同步原语,也就是最常用的线程同步工具。他们是用来为多线程间处理共享数据的操作提供原子性的。怎么做到的呢?其实就是直接让单个线程执行并发任务,同时操作系统阻塞了其他线程直到第一个线程完成它的工作。这么做的原因是一个被阻塞的线程对其他线程是无害的。考虑到阻塞线程的能力,同步原语也称为阻塞机制。
上一篇文章中的任意一种阻塞机制对大多数应用来说能够很好的工作。如果能够正确的使用,他们也是快速的和可靠的。尽管如此,他们还是有一些你可能需要考虑的缺点:
-
他们会阻塞其他线程 - 休眠的线程什么也不做,单纯的等待唤醒信号:这可能会浪费宝贵的时间;
-
他们会卡死你的应用 - 如果一个持有同步原语锁的线程不管什么原因崩溃了,这个锁就永远不会释放了,等待这个锁的线程就永远卡住了;
-
你对休眠哪个线程没什么控制 - 通常是操作系统选择阻塞哪个线程。这会引发一个被称之为优先级反转的不幸结果: 一个执行非常重要任务的高优先级线程被一个低优先级线程阻塞了。
大多数时候你不会关注这些问题,因为他们不影响你应用程序的正确性。另一方面,有时候使线程一直运行是有必要的,特别是你想发挥多处理器/多核硬件的能力,或者你就是不能容忍系统被一个崩溃的线程拖死,或者优先级反转的问题是不容忽视的。
无锁编程来救场
好消息:还有另一种控制多线程应用中并发任务的方法,为了避免上面提到的1),2)和3)点问题,称之为无锁编程,这是一种不用加锁和解锁就可以安全的在多线程之间共享变化数据的技术。
坏消息:这是非常底层的东西。比传统的同步原语比如互斥锁和信号量还底层多了:这次我们会更接近本质。尽管如此,我发现无锁编程是一个很好的思想挑战,也是一个非常好的更好理解计算机如何工作的机会。
无锁编程依赖原子指令,这是CPU直接执行的原子操作。原子指令作为无锁编程的基础,我将在本文剩下的部分首先介绍,然后展示如何利用它做并发控制。
什么是原子指令?
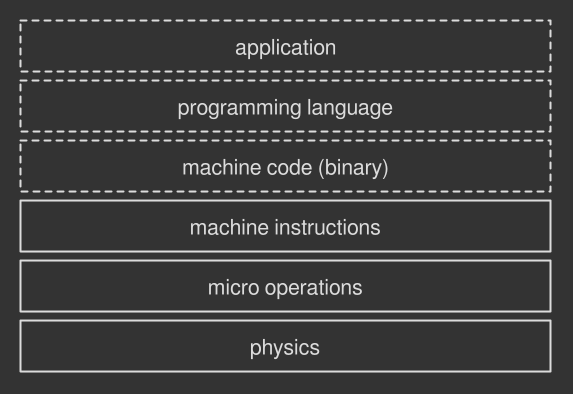
思考计算中执行的任何操作,比如在屏幕上展示一张图片。这个操作是由许多更小的操作构成的:将文件读入内存,解压缩图片,点亮屏幕上的像素等等。如果你不停的细分这些更小的操作,也就是分为更小更小的操作,你最终会不能在分了。此时得到的处理器执行的肉眼可见的最小操作称之为机器指令,也就是硬件可直接执行的命令。
Figure 1. 计算机程序的不同层次。虚线代表软件层次,实线代表硬件层次。
取决于不同的CPU架构,一些机器指令是原子的,也就是单个的,不能切分的,不会被中断的。一些其他的指令则不是原子的:处理器私底下以更小的操作的方式做了更多的工作,这些操作称之为微指令。让我们给出更正式的分类:原子指令是不能在细分的CPU指令。更确切的说,原子指令可以被归为2个主要类型:存储与加载 和读取-修改-写入(RMW)。
存储与加载原子指令
读取-修改-写入(RMW)原子指令
一些更复杂的操作不能够单独用一些简单存储和加载指令来完成。例如,增加存储中的数值需要至少3个原子的加载和存储指令,这就使的增加内存中数值这个操作不是原子的。读取-修改-写入(RMW) 指令可以做到这个,也就有了通过一个原子操作完成多个操作的能力。除了RMW,还有非常多此类的指令。一些CPU架构全部提供,一些则提供一部分,下面列举一些:
-
测试并设置 - 一个原子操作完成往内存中写入1并且返回赋值之前的值;
-
获取并增加 - 一个原子操作完成增加内存中的数值并且返回增加之前的值;
-
比较并交换(CAS) - 比较内存中的数据和提供的数据,如果他们是相同的,将提供的另一个数据写入该内存中。
以上这些操作都是一个原子操作完成多个操作。这是一个非常重要的特性,使得读取-修改-写入指令适合无锁多线程操作。我们很快就会看到为什么适合了。
原子指令的三个层次
以上所有这些指令都属于硬件层面的:他们直接和CPU交互。这种工作方式是非常困难并且不可移植,因为一些指令可能在不同得架构下叫不同得名字,一些指令在不同的处理器模型上则根本不存在!因此,你也不太可能用到这些,除非你在针对特定得机器写非常底层得代码。
上到软件层面,许多操作系统提供了各自的原子指令。姑且称之为原子操作(atomic operations),因为我们正在抽象出物理机器指令对应得原子操作。 例如, Windows系统上可能会用到Interlocked API,这是一组原子方式处理变量得函数。 MacOS则用OSAtomc.h头文件提供的函数做同样的事情。他们肯定是隐藏了硬件的具体实现,但是你还是受限于他们特定的环境。
实现可移植原子操作的最好办法是使用你所选择的编程语言提供的原子操作。比如Java语言中有java.util.concurrent.atomic包;C++提供了std::atomic头文件; Haskell有Data.Atomics包等等。一般来讲,如果一个编程语言能处理多线程,那就很有可能会提供原子操作的支持。这样的话就是编译器(如果是编译语言)或者虚拟机(如果是解析语言)负责从底层操作系统API或者硬件中找到最合适的指令来实现原子操作。

Figure 2. 原子指令和操作的层级。虚线代表软件层次,实线代表硬件层次。
例如,C++ 的编译器GCC通常是直接将 C++语言的原子操作和对象对应到机器指令。如果不能直接映射到硬件上,它也会利用其他可用的原子操作来实现特定操作。最坏情况下,在一个不提供原子操作的平台上,它可能利用其他阻塞策略来实现了,当然了这肯定不是无锁的实现。
在多线程中使用原子操作
我们现在看看原子操作是如何使用的。 考虑增加一个简单的变量,这本来就不是原子操作,因为此操作由3个不同的步骤构成:读取数值,给数值加1,将结果写回。 一般来说,你可能会使用互斥锁来正确实现这个操作(伪代码):
mutex = initialize_mutex()
x = 0
reader_thread()
mutex.lock()
print(x)
mutex.unlock()
writer_thread()
mutex.lock()
x++
mutex.unlock()首先获得互斥锁的线程会继续执行,而其他线程则等待第一个线程执行完毕。
相反的,无锁方案使用了不同的模式:通过原子操作,线程可以随意执行而不用阻塞,例如:
x = 0
reader_thread()
print(load(x))
writer_thread()
fetch_and_add(x, 1)我假设了fetch_and_add()和load()是基于相应的硬件指令的原子操作。 你可能已经发现了,这里并没有使用锁。 并发调用这些函数的多个线程都可以继续执行。load() 函数的原子性将保证不会有读线程读取到未完成修改的数据,同时因为fetch_and_add()的原子性,也不会有写线程能够部分修改数据。
现实世界中的原子操作
现在,上面这个例子显示了原子操作的一个重要特性:他们仅针对原子类型,如boolean型,字符串,整数等。但是真的程序是需要使用同步技术来实现更复杂的数据结构,比如数组,向量,对象,数据向量,对象里包含数据等等。如何用基于原子类型的简单操作来保证复杂数据的原子性?
无锁编程迫使你跳出常规的同步原语来思考问题。你不直接用原子操作保护共享资源,而是用互斥锁或者信号量。同样的,你会基于原子操作构建无锁算法或者无锁数据结构来确定多个线程如何访问你的数据。
例如,上面看到的fetch-and-add操作可以用来实现一个基本的信号量,而这个信号量就可以用来协调多个线程。毫无意外,所有传统的阻塞同步工具都是基于原子操作的实现的。
人们写了很多个无锁数据结构,比如Folly的AtomicHashMap, Boost.Lockfree类库,多生产者/多消费者, 先进先出队列(FIFO),或者诸如读取-复制-更新(RCU)和影子分页(Shadow Paging)等一些算法。从头开始写这些原子工具很困难,更不用说让他们正确工作。这也是大多数时候你可能会使用已经存在的,实战检验过得算法与数据结构,而不是使用自己实现的。
比较并交换(CAS)循环
具体到实际应用,比较并交换循环(CAS loop)可能是无锁编程中最常用的技巧,无论你是使用现成的数据结构或者从头开始实现算法。这是基于对应的比较并交换原子操作(CAS)而且有一个很好的特点:他能支持多个写线程。这是用到复杂系统中的并发算法的一个重要特征。
CAS循环非常有趣是因为他在无锁代码中引入了重复模式,同时引入了用于推理的理论概念。我们进一步看一下。
CAS循环实现
操作系统或者编程语言提供的CAS函数可能是这样的:
boolean compare_and_swap(shared_data, expected_value, new_value);他的入参有共享数据的引用/指针,预期共享数据当前的值以及将要赋值的新值。这个函数只有在shared_date.value == expected_value的情况下才会使用新数据替换原始数据,并且只有数据改变的情况下才返回true。
CAS循环的思路是不停的尝试比较和交换,直到操作成功。每一次尝试都需要给CAS函数传递共享数据的引用/指针,预期的数据和将要赋值的数据。这是和其他并发写线程配合的必要条件:如果其他线程在同步修改数据,也就是共享数据和预期数据不再匹配了,CAS函数就会失败。这样就支持了多个写线程。
假设我们用CAS来实现前面代码片段实现的fetch-and-add算法,实现起来可能是这样的(伪代码):
x = 0
reader_thread()
print(load(x))
writer_thread()
temp = load(x) (1)
while(!compare_and_swap(x, temp, temp + 1)) (2)第(1)行代码加载共享数据,然后尝试和新的数据进行交换,直到交换成功返回true(2)。
交换范式
正如前面说的,CAS循环在许多无锁算法中引入了重复模式:
-
创建共享数据的本地副本;
-
按需修改本地副本;
-
合适的时候,通过交换更新后的数据与之前创建的副本数据来更新共享数据。
第3)点是关键:交换是通过原子操作来保证原子性的。本地写线程针对副本数据做了大部分的脏活累活,等到合适的时候才发布更新到共享数据。这样的话,其他线程只能看到这个共享数据的2种状态:未修改的数据和修改后的数据。由于原子交换,看不到修改过程中的中间状态,或者出错的更新。
这也是哲学上不同于加锁方案的:无锁算法中,多线程仅仅在执行交换的时候才需要交互,其他时候都不被打扰的运行,也感知不到其他线程的存在。多线程之间的交互点缩小了并且被限制在执行原子操作的期间。
一种轻量级加锁形式
上面看到的循环直到成功的策略在许多无锁算法中用到了,被称之为自旋锁(spinlock):一个简单的循环,线程不停的尝试执行操作直到成功。这是一种轻量级的加锁形式,此时线程是实时活跃运行的,不会被操作系统休眠,尽管这个循环成功之前工作不会有进展。相比之下,互斥锁或者信号量中用到的常规锁代价非常高,因为一个挂起/唤醒周期需要大量的底层工作。
ABA问题
行(1)和(2)所示指令虽然有所不同,但不是连续的。另一个线程可能插入中间,再(1)读取完成之后修改共享数据。更确切的说,另一个线程可以将初始数据,假设为A,修改为B,然后在(2)所示的比较并交换操作执行之前再修改回A。执行CAS操作的线程不会发现数据的变化而成功执行交换操作。这就是所谓的ABA问题:有时候你可以简单的直接忽略,如果你的算法就像上面那个一样简单,而有时候你就需要避免此问题,因为这会给你的应用程序引入非常难以发现的问题。幸运的是有几种方式 可以绕过这个问题。
CAS循环可以交换任意的事情
CAS循环经常用来交换指针,这也是比较并交换操作支持的类型之一。当你需要修改复杂的诸如对象或者数组的数据集的时候非常有用:创建本地数据副本,按需修改这个副本,合适的时候交换本地副本数据和全局共享数据的指针。这样的话全局共享数据就指向了本地副本数据在内存中指针,其他线程就会看到更新后的最新数据。
无锁和无等待
每个基于原子操作的算法或者数据结构都可以归为2类:无锁的 或者无等待的。当你要评估基于原子操作的类库对你应用程序性能的影响时,这是一个非常重要的不同点。
无锁算法允许其他线程继续执行有用的工作,尽管有一个线程正在忙等。换句话说,至少有一个线程是可以继续执行的。CAS循环是一个非常好的无锁算法例子,因为循环的过程中如果有一些交换尝试失败了,一定是因为另一个线程成功修改了共享数据。尽管如此,无锁算法可能会在无法预知的时间内不停的忙等,尤其是有许多个线程在同时竞争同一个共享数据:更确切的说,当竞争非常激烈的时候。极端情况下,一个无锁算法的CPU资源效率可能远远不及让线程阻塞休眠的互斥锁。
相比之下,在无等待算法中(无锁算法的子集),任何线程都能够在有限的步骤内完成工作,无论执行速度是怎样的,或者其他线程的工作负载水平是怎样的。本文中基于fetch-and-add操作的第一个代码片段就是一个无等待算法实例:没有循环,没有重试,就是干净的业务流。还有,无等待算法是容错的:任何其他线程的失败,或者执行速度的波动都不会使当前线程结束不了工作。这些特性使得无等待算法非常适合复杂的实时系统,因为这里并发代码的行为可预知是必要的。
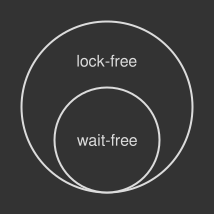
Figure 3. 无等待算法是无锁算法的子集
无等待是并发代码非常需要的,但也是很难获得的特性。总而言之,无论你正在构建一个阻塞的,无锁的还是无等待的算法,黄金法则是你一定要做基准测试并且衡量测试结果。有时候旧时的互斥锁比时髦的同步原语性能要好,尤其是并发任务的复杂度非常高的时候。
写到最后
原子操作是无锁编码的必要组成,甚至在单处理器的机器上也是。没有原子性,一个线程可能在事务中途被中断,可能会导致不一致的数据状态。本文中,我仅仅是浅尝辄止:一旦你把多核/多线程考虑进去,就打开了新世界。顺序一致性 和内存屏障是非常关键的部分,如果要充分利用无锁算法,就不应该被忽视。我将在下一文章中讨论这些主题。
参考
-
Preshing on Programming - An Introduction to Lock-Free Programming
-
Preshing on Programming - Atomic vs. Non-Atomic Operations
-
Preshing on Programming - You Can Do Any Kind of Atomic Read-Modify-Write Operation
-
StackOverflow - Do I need a mutex for reading?
-
StackOverflow - Will atomic operations block other threads?
-
StackOverflow - Spinlock vs Busy wait
-
GCC Wiki - Atomics
-
GCC Wiki - Memory model synchronization modes
-
Threading Building Blocks - Atomic Operations
-
Just Software Solutions - Definitions of Non-blocking, Lock-free and Wait-free
-
Wikipedia - Compare-and-swap
-
Wikipedia - Read-modify-write
-
Wikipedia - Test-and-set
-
Tyler Neely - Fear and Loathing in Lock-Free Programming
-
Jason Gregory - Game Engine Architecture, Third Edition
-
AA.VV. - Evaluating the Cost of Atomic Operations on Modern Architectures
-
Herb Sutter, CppCon 2014 - Lock-Free Programming (or, Juggling Razor Blades), Part 1
-
Herb Sutter, CppCon 2014 - Lock-Free Programming (or, Juggling Razor Blades), Part 2
-
Maurice Herlihy - Wait-free synchronization
-
Fedor Pikus, CppCon 2014 - Read, Copy, Update, then what? RCU for non-kernel programmers
-
1024cores - Lockfree Algorithms
-
Microsoft - Lockless Programming Considerations for Xbox 360 and Microsoft Windows
-
Brian Goetz, IBM - Going Atomic
本文译自https://www.internalpointers.com/post/lock-free-multithreading-atomic-operations,英文读者可直接阅读原文。